






乍一看到某个问题,你会觉得很简单,其实你并没有理解其复杂性。当你把问题搞清楚之后,又会发现真的很复杂,于是你就拿出一套复杂的方案来。实际上,你的工作只做了一半,大多数人也都会到此为止……。但是,真正伟大的人还会继续向前,直至找到问题的关键和深层次原因,然后再拿出一个优雅的、堪称完美的有效方案。—— 乔布斯
注意本文档建立在playwright-nodejs1.16版本基础上,本教程并未完全参照官方文档(主要是在这个版本之前就已经接触playwright-python
为什么选择playwright
Playwright可在所有现代浏览器中实现快速,可靠和强大的自动化。本指南涵盖了这些关键区别因素,以帮助您为自动化测试选择合适的工具。
- 支持所有浏览器
- 快速可靠的执行
- 强大的自动化功能
- 与您的工作流程整合
- 相关限制
对于所有浏览器的支持
- 在Chromium,Firefox和WebKit上进行测试。Playwright拥有适用于所有现代浏览器的完整API覆盖,包括Google Chrome和Microsoft Edge(带有Chromium),Apple Safari(带有WebKit)和Mozilla Firefox。
- 跨平台的WebKit测试。使用Playwright,使用适用于Windows,Linux和macOS的WebKit构建,测试您的应用程序在Apple Safari中的行为。在本地和CI上进行测试。
- 测试手机。使用设备仿真在移动Web浏览器中测试您的自适应Web应用程序。
- 无报文头与有报文头。Playwright支持所有浏览器和所有平台的无头(无浏览器UI)和有头(有浏览器UI)模式。有报文头模式适用于调试,而无报文头适用于CI / cloud执行。
快速可靠的执行
- 自动等待APIs。Playwright交互会自动等待直到元素准备就绪。这样可以提高可靠性并简化测试编写流程。
- 无超时自动化。Playwright会接收浏览器信号,例如网络请求,页面导航和页面加载事件,以消除导致睡眠中断的烦恼。
- 与浏览器上下文保持并行。对于多个并行孤立的浏览器上下文可执行环境重复使用一个单独的浏览器实例。
- 弹性元素选择器。Playwright可以依靠面向用户的字符串(例如文本内容和可访问性标签)来选择元素。这些字符串比紧耦合到DOM结构的选择器更具弹性。
强大的自动化功能
- 多个域,页面和框架。Playwright是一种进程外自动化驱动程序,不受页面内JavaScript执行范围的限制,并且可以自动执行具有多个页面的方案。
- 强大的网络控制。Playwright引入上下文范围的网络拦截以便进行终止或者模拟网络请求。
- 现代网络功能。Playwright通过插入阴的选择器,地理位置,权限,Web Worker和其他现代Web API支持Web组件。
- 涵盖所有场景的能力。支持文件下载和上传,进程外iframe,原生输入事件,甚至是深色模式。
- 官方同步版本的 API。
- 方便导入导出 Cookies。
- 轻量级设置和切换代{过}{滤}理。
- 支持丰富的选择表达式。
- Playwright 支持处理页面弹出的窗口,模拟键盘,模拟鼠标拖动(用于滑动验证码),下载文件等等各种功能,请查看官方文档吧,这里不赘述了。
与您的工作流进行集成
单流程安装。运行
npm i -D playwright
自动下载浏览器相关依赖程序,以便您的团队快速上手合作。
- TypeScript支持。Playwright附带内置类型,可实现自动完成和其他优点。
- 调试工具。Playwright与编辑器调试器(例如vscode)和浏览器开发工具一起使用,以暂停执行并检查网页。
- 将测试部署到CI。第一方Docker映像和GitHub Actions将测试部署到您首选的CI / CD提供程序
- 调试工具:通过 VS Code 完成自动化的调试。
- 语言绑定:Playwright 支持多种编程语言:Python、Node.js、.NET、Java
局限性
- 旧版Edge和IE11支持。Playwright不支持旧版Microsoft Edge或IE11(弃用通知)。支持新的Microsoft Edge(在Chromium上)。
- Java语言绑定:Playwright API目前无法在Java或Ruby中使用。这是暂时的限制,因为Playwright旨在支持任何语言的绑定。
- 在真实的移动设备上进行测试:Playwright使用桌面浏览器来模拟移动设备。如果您有兴趣在实际的移动设备上运行,请支持此问题。
- 目前还在持续更新,许多API都是实验性的(我就被坑了)。
题外话:Playwright团队是微软把puppeteer团队挖过去做的,所以基本上puppeteer的特性Playwright都有,并在puppeteer基础上做了很多优化。
入门
前置知识
- npm的基本使用
- js的基本用法
- html基本结构和语法
引例
- 安装所需环境
npm i -D playwright- 编写一个基本框架程序
const { chromium } = require('playwright');//引用所需包,这里用了chromium内核浏览器
//你可以选择(chromium, firefox and webkit)内核的浏览器
(async () => {//异步实现程序,因为官方API返回的都是promise类型
const browser = await chromium.launch();//模拟启动一个类似无痕chrome浏览器
// 中间可以添加各种所需代码
await browser.close();//关闭浏览器
})();- 实现一个有意义的程序(访问www.baidu.com网站并截图)
const { chromium } = require('playwright');//引用模拟浏览器
(async () => {
const browser = await chromium.launch();//模拟打开浏览器,设置有头模式,并通过slowMo属性减慢浏览器的每一步操作
const context = await browser.newContext();//建立context
const page = await context.newPage();//模拟打开一个浏览器的标签页
await page.goto('https://www.baidu.com/');//模拟访问网站url
await page.screenshot({ path: `example.png` });//对网页进行截图并保存为example.png
await page.close();//关闭网页
await context.close();//关闭context
await browser.close();//关闭浏览器
})();<br/>
无头与有头
有头和无头你可以理解为是否让程序静默执行,还是显示他的模拟操作(即显示他的模拟浏览器操作,可视化)(即有程序浏览器UI)
上面的程序没有设置有头或无头,所以默认是无头的。
我们想要看看程序是如何模拟的,可以开启有头模式。
const { chromium } = require('playwright');//引用模拟浏览器
(async () => {
const browser = await chromium.launch({ headless: false, slowMo: 50 });//模拟打开浏览器,设置有头模式,并通过slowMo属性减慢浏览器的每一步操作
const context = await browser.newContext();//建立context
const page = await context.newPage();//模拟打开一个浏览器的标签页
await page.goto('https://www.baidu.com/');//模拟访问网站url
await page.screenshot({ path: `example.png` });//对网页进行截图并保存为example.png
await page.close();//关闭网页
await context.close();//关闭context
await browser.close();//关闭浏览器
})();录制操作直接生成代码(杀手级
playwright可以通过录制的功能将你对浏览器的操作录制下来直接生成代码,极大地提高了开发效率。我想,这对新手也极其友好,不会写的操作就直接录制生成。
我们可以通过下方命令行
npx playwright codegen wikipedia.org -o test.jswikipedia.org 是访问的网站,可以不加,自己手动在地址栏输入
-o 后面的是生成代码保存的文件名称,当你关闭浏览器时就会自动生成该文件
//命令行还有一些参数
// -o, --output <file name> 保存脚本到该文件
// --target <language> 指定生成语言 test,node.js, python, java, .net;默认是test
// -h, --help 查看帮助命令模拟移动浏览器
没错,有些网页在手机上显示才是正常的,有时候我们需要特定的手机环境自动化操作,而Playwright 也提供了相关了驱动直接设置浏览器打开方式。还内置了常用的手机 DPI 设置。我们继续举截图的例子。
const { chromium,devices } = require('playwright');//引用模拟浏览器
(async () => {
const browser = await chromium.launch({ headless: false, slowMo: 50 });//模拟打开浏览器,设置有头模式,并通过slowMo属性减慢浏览器的每一步操作
const phoneD = devices['iPhone 11'];//得到一个模拟移动设备
const context = await browser.newContext({ ...phoneD });//建立context,并设置模拟仿真移动设备
const page = await context.newPage();//模拟打开一个浏览器的标签页
await page.goto('https://www.baidu.com/');//模拟访问网站url
await page.screenshot({ path: `example.png` });//对网页进行截图并保存为example.png
await page.close();//关闭网页
await context.close();//关闭context
await browser.close();//关闭浏览器
})();
我们可选择的默认的移动设备有很多:
你甚至还可以设置浏览器的暗黑模式:
const context = await browser.newContext({
colorScheme: 'dark' // or 'light'
});你也可以设置浏览器的大小
await page.setViewportSize({
width: 640,
height: 480,
});获取网页内容
访问baidu.com我们可以看到"使用百度..."这些内容被一个id为index-copyright的a标签包裹。
如果我们按照控制台获取元素的方式(用jquery的方式),就是:
> $("#index-copyright").text()
< '使用百度前必读 Baidu 京ICP证030173号'那我们用playwright可以用以下方式来实现
await page.$('#index-copyright').innerText();完整的例子如下:
const { chromium,devices } = require('playwright');//引用模拟浏览器
(async () => {
const browser = await chromium.launch({ headless: false, slowMo: 50 });//模拟打开浏览器,设置有头模式,并通过slowMo属性减慢浏览器的每一步操作
const phoneD = devices['iPhone 11'];//得到一个模拟移动设备
const context = await browser.newContext({ ...phoneD });//建立context,并设置模拟仿真移动设备
const page = await context.newPage();//模拟打开一个浏览器的标签页
await page.goto('https://www.baidu.com/');//模拟访问网站url
const bak = await page.$('#index-copyright');
console.log((await bak.innerText()));
await page.close();//关闭网页
await context.close();//关闭context
await browser.close();//关闭浏览器
})();输出结果:
使用百度前必读 Baidu 京ICP证030173号input输入和按钮点击
我们可以通过page.fill()来填充(即填写)我们的input,通过page.click()来点击我们的元素(例如按钮button)
当然在输入和点击之前我们都要指定一个对象,就是这些page.click()和page.fill()需要输入参数。我们依然可以像上面获取元素内容一样通过元素选择器来指定对象。其中page.fill()还需要额外指定输入的内容。我们来看看下面的例子,理解一下:
const { chromium} = require('playwright');//引用模拟浏览器
(async () => {
const browser = await chromium.launch({ headless: false, slowMo: 50 });//模拟打开浏览器,设置有头模式,并通过slowMo属性减慢浏览器的每一步操作
const context = await browser.newContext();//建立context
const page = await context.newPage();//模拟打开一个浏览器的标签页
await page.goto('https://www.baidu.com/');//模拟访问网站url
await page.fill('#kw','盲盒功能模块');//在编辑框输入文字
await page.click('#su');//点击搜索按钮
await page.waitForTimeout(1000);//由于网页搜索需要一定时间,我们需要先等待他内容显示后再截图(当然只推荐新手使用waitfortimeout
await page.screenshot({ path: `example.png` });//对网页进行截图并保存为example.png
await page.close();//关闭网页
await context.close();//关闭context
await browser.close();//关闭浏览器
})();如果我们是仿真移动设备,许多操作没有点击事件,只有触摸按压事件,我们则需要page.tap()代替page.click()
进阶
访问指定网页
访问网页和跳转网页都可以使用page.goto()。
按照官网文档,调用 page.goto(url) 后页面加载过程:
- 设定 url
- 通过网络加载解析页面
- 触发 page.on("domcontentloaded") 事件
- 执行页面的 js 脚本,加载静态资源
- 触发 page.on("laod") 事件
- 页面执行动态加载的脚本
- 当 500ms 都没有新的网络请求的时候,触发 networkidle 事件
page.goto(url) 会跳转到一个新的链接。默认情况下 Playwright 会等待到 load 状态。如果我们不关心加载的 CSS 图片等信息,可以改为等待到 domcontentloaded 状态,如果页面是 ajax 加载,那么我们需要等待到 networkidle 状态。如果 networkidle 也不合适的话,可以采用 page.wait_for_selector 等待某个元素出现。不过对于 click 等操作会自动等待。
await page.goto('https://example.com', { waitUntil: 'networkidle' });更多的选择器表达式
在上面的代码中,我们使用了 CSS 表达式(比如#button)来选取元素。实际上,Playwright 还支持 XPath 和自己定义的两种简单表达式,并且是自动识别的。
// 通过文本选择元素,这是 Playwright 自定义的一种表达式
page.click("text=login")
// 直接通过 id 选择
page.click("id=login")
// 通过 CSS 选择元素
page.click("#search")
// 除了常用的 CSS 表达式外,Playwright 还支持了几个新的伪类
// :has 表示包含某个元素的元素
page.click("article:has(div.prome)")
// :is 用来对自身做断言
page.click("button:is(:text('sign in'), :text('log in'))")
// :text 表示包含某个文本的元素
page.click("button:text('Sign in')") // 包含
page.click("button:text-is('Sign is')") // 严格匹配
page.click("button:text-matches('\w+')") // 正则
// 还可以根据方位匹配
page.click("button:right-of(#search)") // 右边
page.click("button:left-of(#search)") // 左边
page.click("button:above(#search)") // 上边
page.click("button:below(#search)") // 下边
page.click("button:near(#search)") // 50px 之内的元素
// 通过 XPath 选择
page.click("//button[@id='search'])")
// 所有 // 或者 .. 开头的表达式都会默认为 XPath 表达式。对于 CSS 表达式,还可以添加前缀css=来显式指定,比如说 css=.login 就相当于 .login.
除了上面介绍的四种表达式以外,Playwright 还支持使用 >> 组合表达式,也就是混合使用四种表达式。
page.click('css=nav >> text=Login')虽然有这么多种选择器,但我们根本不需要去特别关注这些。因为我们可以通过代码录制生成或者通过浏览器调试工具复制某个元素的选择器内容。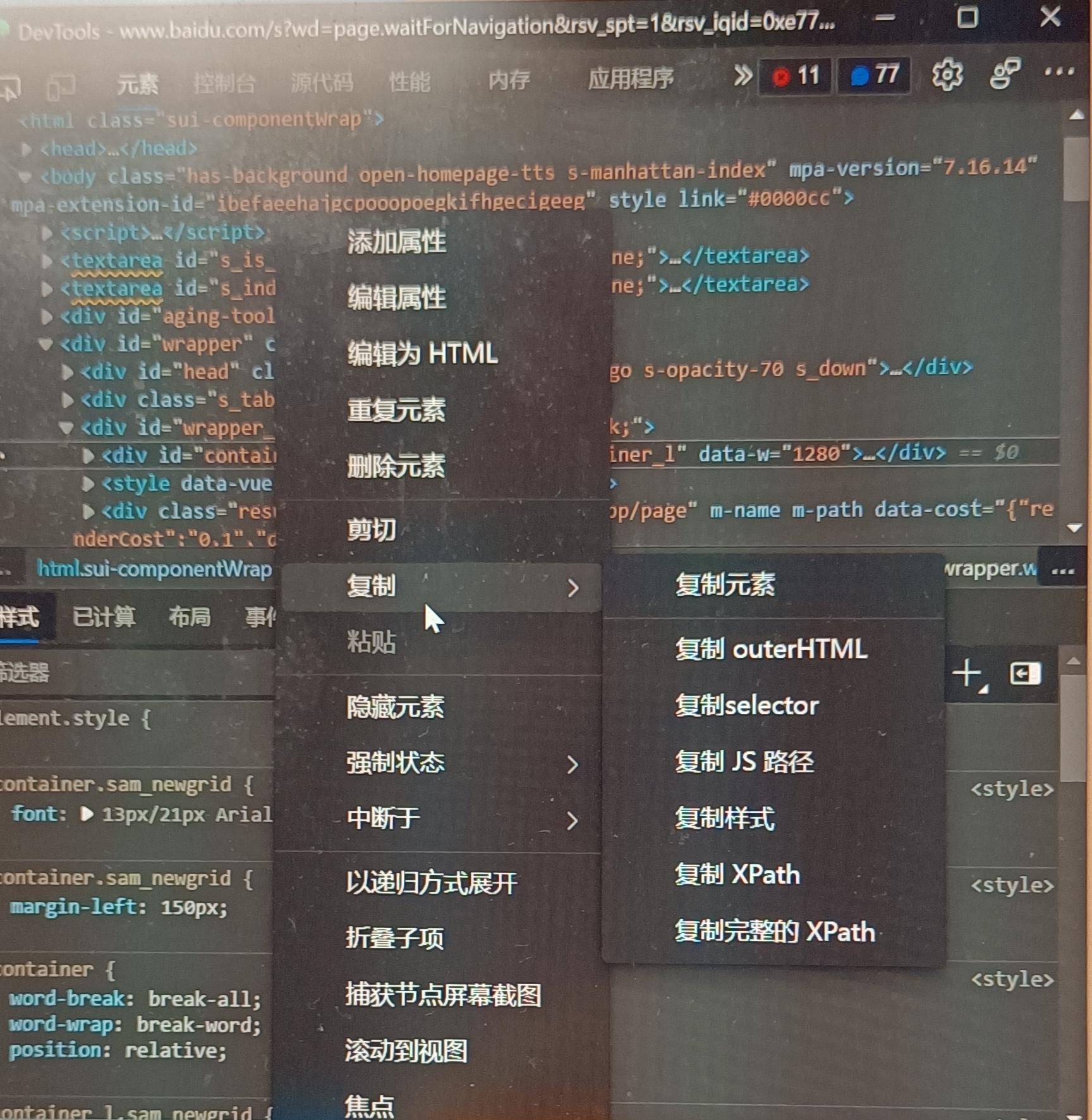
浏览器复制完整xpath的时候最开头只有一个/所以使用xpath选择器时需要补上一个/即//
这么多种选择方式,我们需要选择一种网页结构变动依然不会失效的最稳定的选择方式。
获取更多元素属性的方式
我们可以直接从整个page中获取某个元素属性或子元素属性,也可以通过元素获取子元素属性或者本身的属性。
page.$(selector)//获取某个元素
page.url() //url
page.title() //title
page.content() //获取页面全文
page.innerText(selector) //element.inner_text()获取里面的文本
page.innerHtml(selector)//获取被包裹的html代码
page.textContent(selector)//直接获取文本
page.getAttribute(selector, attr)//获取元素属性
//eval用于获取 DOM 中的值
page.$eval(selector, js_expression)
//比如:
search_value = page.$eval("#search", "el => el.value")
//evaluate 用于获取页面中 JS 中的数据,比如说可以读取 window 中的值
result = page.$eval("([x, y]) => Promise.resolve(x * y)", [7, 8])上面是我们获取单个数据的方式,但假如我们需要获取多组数据该怎么办呢?
比如上面的排行榜(https://movie.douban.com/chart),我想获取排行榜上的电影名称(按顺序,该怎么做呢?
像这种数据在网页一般都有固定的代码结构,我们只需要分析一下。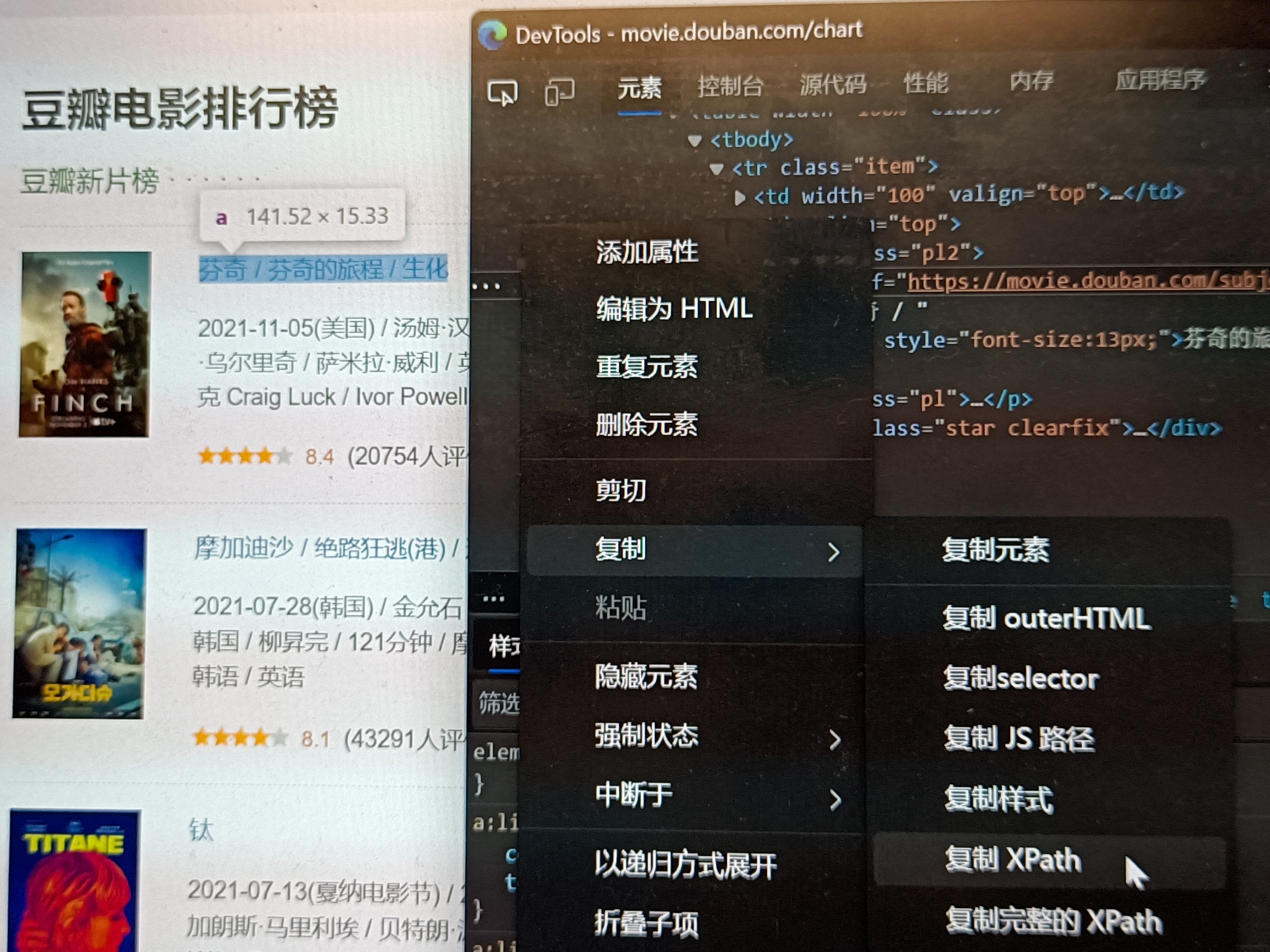
我们先选中其中一个数据的元素右键复制他的xpath地址:
//*[@id="content"]/div/div[1]/div/div/table[1]/tbody/tr/td[2]/div/a然后我们看到"table[1]/tbody/tr/td[2]"他写着table[1],观察他的html代码结构,我们知道一个table里有一个电影介绍。所以我们要拿到多个table里面的"/tbody/tr/td[2]/div/a"的文字即可。但是我们不可能逐个获取他的内容。怎么办呢?我们把xpath地址改为如下:
//*[@id="content"]/div/div[1]/div/div/table/tbody/tr/td[2]/div/a当我们不指定第几个table的时候,他就可以代表全部的table。
可是我们用常规的page.$()或者innerText()之类的却发现只能获取到第一个数据。Playwright提供page.$$()来返回多个结果。我们可以用page.$$()来实现。
const { chromium } = require('playwright');//引用模拟浏览器
(async () => {
const browser = await chromium.launch({ headless: false, slowMo: 50 });//模拟打开浏览器,设置有头模式,并通过slowMo属性减慢浏览器的每一步操作
const context = await browser.newContext();//建立context
const page = await context.newPage();//模拟打开一个浏览器的标签页
await page.goto('https://movie.douban.com/chart');//模拟访问网站url
const elements = await page.$$("//*[@id=\"content\"]/div/div[1]/div/div/table/tbody/tr/td[2]/div/a");//这里返回的是一串array。
for (let i=0; i < elements.length; ++i) {
console.log(await elements[i].innerText());
}
await page.close();//关闭网页
await context.close();//关闭context
await browser.close();//关闭浏览器
})();芬奇 / 芬奇的旅程 / 生化
摩加迪沙 / 绝路狂逃(港) / 逃出摩加迪休(台)
钛
神偷军团 / 活死人军团前传 / 行盗之师
羊崽 / 羊惧(港/台) / Lamb
在糟糕的日子里 / 致命之旅 / The Trip
驾驶我的车 / Drive My Car
东北恋哥 / 东北恋歌 / 当男人恋爱时 中国大陆版
关于我妈的一切 / All About My Mother
深宅 / 深宅 / 深水妖宅必要的等待才能有更多操作
Playwright 会自动等待元素处于可操作的稳定状态。但是有时候我们会发现这个并不称心如意,所以我们可以手动设置一些等待操作。我们可以用 page.wait_for_* 函数来手工等待:
page.waitForRequest()//等待某个请求
page.waitForEvent()//等待某个事件
page.waitForURL()//等待某个URL
page.waitForTimeout(1000)//等待1000ms的时间
page.waitForSelector()//等待某个元素加载
page.waitForResponse()//等待某个回应
page.waitForNavigation()//等待页面重定向并加载完毕
page.waitForLoadState()//等待某个状态被激发
page.waitForFunction()//等待某个函数被执行完毕
前面有一个百度搜索然后截图的例子就使用了等待来实现功能,我们可以再来看一遍:
const { chromium} = require('playwright');//引用模拟浏览器
(async () => {
const browser = await chromium.launch({ headless: false, slowMo: 50 });//模拟打开浏览器,设置有头模式,并通过slowMo属性减慢浏览器的每一步操作
const context = await browser.newContext();//建立context
const page = await context.newPage();//模拟打开一个浏览器的标签页
await page.goto('https://www.baidu.com/');//模拟访问网站url
await page.fill('#kw','盲盒功能模块');//在编辑框输入文字
await page.click('#su');//点击搜索按钮
await page.waitForTimeout(1000);//由于网页搜索需要一定时间,我们需要先等待他内容显示后再截图(当然只推荐新手使用waitfortimeout
await page.screenshot({ path: `example.png` });//对网页进行截图并保存为example.png
await page.close();//关闭网页
await context.close();//关闭context
await browser.close();//关闭浏览器
})();无头?速速显形!
当我们使用无头模式的时候,我们看不到浏览器背着我们干了什么勾当。呜呜呜~这时候就需要我们委托playwright来监控浏览器的一举一动。它提供了一个video录制功能。具体的使用方法和使用例子直接看下面:
const { chromium} = require('playwright');//引用模拟浏览器
(async () => {
const browser = await chromium.launch();//模拟打开浏览器,设置有头模式,并通过slowMo属性减慢浏览器的每一步操作
const context = await browser.newContext({//设置video录制保存的路径
recordVideo: {
dir: 'videos/'
}
});//建立context,并设置模拟仿真移动设备
const page = await context.newPage();//模拟打开一个浏览器的标签页
await page.goto('https://www.baidu.com/');//模拟访问网站url
await page.fill('#kw','盲盒功能模块');//在编辑框输入文字
await page.click('#su');//点击搜索按钮
await page.waitForSelector('//*[@id="page"]/div/a[10]');//等待网页框架加载完毕
await page.waitForTimeout(3000);//由于网页图片加载需要一定时间,我们需要先等待他内容显示后再截图(当然只推荐新手使用waitfortimeout
await page.close();//关闭网页
await context.close();//关闭context
await browser.close();//关闭浏览器
})();由于文档无法上传视频,请自行操作。
网页不合意?JS/CSS来帮忙
我们有时候使用playwright发现有些浏览器的功能没有支持或者说对网页某些地方不满意,没法直接用playwright完成自动化。这时候我们就可以借助js/css直接注入到网页来改变网页达到我们的目的。
例如我想对网页进行自动化打印,但发现playwright没有这个功能(可能没有)。那我们可以找一个折中的办法。首先,我们可以使用screenshot截图然后批量打印图片的方式,但发现如果页面过长,截图好像没法对整个页面截图。这个办法行不通,我们可以接着想。我们发现playwright提供了一个生成pdf的功能,仔细一想,浏览器打印的时候也有保存为pdf的选项。这个莫非就相当于浏览器打印时的另存为pdf?显然不是,我们实践可以发现,生成的pdf和我们需要打印的样式有所区别。
例如我们想要的打印效果:
而我们直接用page.pdf生成的却是:
const { chromium } = require('playwright');//引用模拟浏览器
(async () => {
const browser = await chromium.launch({ headless: true, slowMo: 50 });//模拟打开浏览器,设置无头模式,并通过slowMo属性减慢浏览器的每一步操作
const context = await browser.newContext();//建立context
const page = await context.newPage();//模拟打开一个浏览器的标签页
await page.goto('https://www.baidu.com/');//模拟访问网站url
await page.pdf({ path: `document.pdf` });//生成pdf必须无头模式
await page.close();//关闭网页
await context.close();//关闭context
await browser.close();//关闭浏览器
})();
我们可以通过加入一段css/js代码(page.addScriptTag/page.addStyleTag)来改善这一情况
const { chromium } = require('playwright');//引用模拟浏览器
(async () => {
const browser = await chromium.launch({ headless: true, slowMo: 50 });//模拟打开浏览器,设置无头模式,并通过slowMo属性减慢浏览器的每一步操作
const context = await browser.newContext();//建立context
const page = await context.newPage();//模拟打开一个浏览器的标签页
await page.goto('https://www.baidu.com/');//模拟访问网站url
await page.addScriptTag({content:'document.querySelector("#u1").setAttribute("style","display:none")'})
await page.pdf({ path: `document.pdf` });//生成pdf必须无头模式
await page.close();//关闭网页
await context.close();//关闭context
await browser.close();//关闭浏览器
})();
上面改善的js完全可以用page.addStyleTag代替
获得了满意的pdf就可以对其打印啦。
复用 Cookies 等认证信息
playwright支持Cookies、Local storage、Session storage多种保存认证状态的方式。在 Puppeteer 中,复用 Cookies 也是一个老大难问题了。这个是 Playwright 特别方便的一点,他可以直接导出 Cookies 和 LocalStorage, 然后在新的 Context 中使用。下面是一个登录信息保存与复用的例子。如果保存了之前登录的cookie,我们访问网页的时候他就不会跳转页面,再要求我们登录。
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch({
headless: false
});
const context = await browser.newContext({ storageState: 'auth.json' });//这里是复用之前auth.json里面的cookie信息
const page = await context.newPage();
await page.goto('https://skl.hduhelp.com/#/english/list');
await page.fill('[placeholder="职工号/学号"]', 'yourid');
await page.fill('[placeholder="密码"]', 'yourpd');
await page.check('input[type="checkbox"]');
await Promise.all([
page.waitForNavigation(/*{ url: 'https://skl.hduhelp.com/#/call/course' }*/),
page.click('text=登 录')
]);
await context.storageState({ path: 'auth.json' });//这里保存我们的cookie等信息到auth.json
await context.close();
await browser.close();
})();监听网络事件
通过 page.on(event, fn) 可以来注册对应事件的处理函数,其中比较重要的就是 request 和 response 两个事件。
可以通过 page.on("request") 和 page.on("response") 来监听请求和响应事件。
const { chromium } = require('playwright');
(async () => {
const browser = await chromium.launch({
headless: false
});
const context = await browser.newContext({ storageState: 'auth.json' });//这里是复用之前auth.json里面的cookie信息
const page = await context.newPage();
await page.goto('https://skl.hduhelp.com/#/english/list');
await page.fill('[placeholder="职工号/学号"]', 'yourid');
await page.fill('[placeholder="密码"]', 'yourpd');
await page.check('input[type="checkbox"]');
await Promise.all([
page.waitForNavigation(/*{ url: 'https://skl.hduhelp.com/#/call/course' }*/),
page.click('text=登 录')
]);
await page.on('response', async response => {
if (response.url().includes("yourapi") && response.status() === 200) {//如果找到符合的正确返回api
console.log((await response.body())); //输出我们api返回的data
}
})
await context.storageState({ path: 'auth.json' });//这里保存我们的cookie等信息到auth.json
await context.close();
await browser.close();
})();其中 request 和 response 的属性和方法,可以查阅文档:https://playwright.dev/docs/api/class-request/
通过 context.route, 还可以伪造修改拦截请求等。比如说,拦截所有的图片请求以减少带宽占用:
const { chromium} = require('playwright');//引用模拟浏览器
(async () => {
const browser = await chromium.launch({ headless: false, slowMo: 50 });//模拟打开浏览器,设置有头模式,并通过slowMo属性减慢浏览器的每一步操作
const context = await browser.newContext();//建立context,并设置模拟仿真移动设备
const page = await context.newPage();//模拟打开一个浏览器的标签页
await page.goto('https://www.baidu.com/');//模拟访问网站url
await page.fill('#kw','盲盒功能模块');//在编辑框输入文字
// route 的参数默认是通配符,也可以传递编译好的正则表达式对象
await page.route("**/*.{png,jpg,jpeg}", route => route.abort());//拦截图片的请求=>即直接伪装成服务器给请求发回响应
await page.click('#su');//点击搜索按钮
await page.waitForTimeout(1000);//由于网页搜索需要一定时间,我们需要先等待他内容显示后再截图(当然只推荐新手使用waitfortimeout
await page.screenshot({ path: `example.png` });//对网页进行截图并保存为example.png
await page.close();//关闭网页
await context.close();//关闭context
await browser.close();//关闭浏览器
})();
我们甚至可以玩一些骚操作(什么请求都不给他发出去,还给他一个404:
const { chromium} = require('playwright');//引用模拟浏览器
(async () => {
const browser = await chromium.launch({ headless: false, slowMo: 50 });//模拟打开浏览器,设置有头模式,并通过slowMo属性减慢浏览器的每一步操作
const context = await browser.newContext();//建立context,并设置模拟仿真移动设备
const page = await context.newPage();//模拟打开一个浏览器的标签页
await page.goto('https://www.baidu.com/');//模拟访问网站url
await page.fill('#kw','盲盒功能模块');//在编辑框输入文字
// route 的参数默认是通配符,也可以传递编译好的正则表达式对象
await page.route('**/*', route => {
route.fulfill({
status: 404,
contentType: 'text/plain',
body: 'Not Found!'
});
});//拦截所有请求=>即直接伪装成服务器给请求发回响应
await page.click('#su');//点击搜索按钮
await page.waitForTimeout(1000);//由于网页搜索需要一定时间,我们需要先等待他内容显示后再截图(当然只推荐新手使用waitfortimeout
await page.screenshot({ path: `example.png` });//对网页进行截图并保存为example.png
await page.close();//关闭网页
await context.close();//关闭context
await browser.close();//关闭浏览器
})();
除了拦截,我们还可以过滤:
对请求header符合的一律通过。
await page.route('**/*', (route, request) => {
// Override headers
const headers = {
...request.headers(),
foo: 'bar', // set "foo" header
origin: undefined, // remove "origin" header
};
route.continue({headers});
});其中 route 对象的相关属性和方法,可以查阅文档:https://playwright.dev/docs/api/class-route
灵活设置代{过}{滤}理
Playwright 还可以很方便地设置代{过}{滤}理。Puppeteer 在打开浏览器之后就无法在更改代{过}{滤}理了,对于爬虫类应用非常不友好,而 Playwright 可以通过 Context 设置代{过}{滤}理,这样就非常轻量,不用为了切换代{过}{滤}理而重启浏览器。
context = await browser.newContext(
proxy={"server": "http://example.com:3128", "bypass": ".example.com", "username": "", "password": ""}
)我们还可以设置useragent
context = await browser.newContext({
userAgent: 'My user agent'
});更多功能请见:https://playwright.dev/docs/emulation
代码封装
所有脚本逻辑都写在一起不便于关注点分离,因此官方建议对于逻辑较复杂的脚本,可以将在一个页面内的各个逻辑代码段封装为一个个类中的方法。
// models/Search.js
class SearchPage {
constructor(page) {
this.page = page;
}
async navigate() {
await this.page.goto('https://bing.com');
}
async search(text) {
await this.page.fill('[aria-label="Enter your search term"]', text);
await this.page.keyboard.press('Enter');
}
}
module.exports = { SearchPage };// search.spec.js
const { SearchPage } = require('./models/Search');
// In the test
const page = await browser.newPage();
const searchPage = new SearchPage(page);
await searchPage.navigate();
await searchPage.search('search query');
核心概念
有许多的API和功能,概念都可以通过官方文档挖掘。但是有些功能都是实验性的,注意使用。
Browser
一个Browser是一个Chromium, Firefox 或 WebKit(plarywright支持的三种浏览器)的实例plarywright脚本通常以启动浏览器实例开始,以关闭浏览器结束。浏览器实例可以在headless(没有 GUI)或head模式下启动。
启动browser实例是比较耗费资源的,plarywright做的就是如何通过一个browser实例最大化多个BrowserContext的性能。
const { chromium } = require('playwright'); // Or 'firefox' or 'webkit'.
const browser = await chromium.launch({ headless: false });
await browser.close();具体的相关API和属性可以看这里:https://playwright.dev/docs/api/class-browser/
BrowserContext
一个BrowserContex就像是一个独立的匿名模式会话(session),非常轻量,但是又完全隔离。
const browser = await chromium.launch();
const context = await browser.newContext();每个browser实例可有多个BrowserContex,且完全隔离。比如可以在两个BrowserContext中登录两个不同的账号,也可以在两个 context 中使用不同的代{过}{滤}理。
context还可用于模拟涉及移动设备、权限、区域设置和配色方案的多页面场景。
const { devices } = require('playwright');
const iPhone = devices['iPhone 11 Pro'];
const context = await browser.newContext({
...iPhone,
permissions: ['geolocation'],
geolocation: { latitude: 52.52, longitude: 13.39},
colorScheme: 'dark',
locale: 'de-DE'
});具体的相关API和属性可以看这里:https://playwright.dev/docs/api/class-browsercontext/
Page 和 Frame
一个BrowserContext可以有多个page,每个page代表一个tab或者一个弹窗。page用于导航到URL并与page内的内容交互。
// Create a page.
const page = await context.newPage();
// Navigate explicitly, similar to entering a URL in the browser.
await page.goto('http://example.com');
// Fill an input.
await page.fill('#search', 'query');
// Navigate implicitly by clicking a link.
await page.click('#submit');
// Expect a new url.
console.log(page.url());
// Page can navigate from the script - this will be picked up by Playwright.
window.location.href = 'https://example.com';一个page可以有多个frame对象,但只有一个主frame,所有page-level的操作(比如click),都是作用在主frame上的。page的其他frame会打上iframe HTML标签,这些frame可以在内部操作实现访问。
// Get frame using the frame's name attribute
const frame = page.frame('frame-login');
// Get frame using frame's URL
const frame = page.frame({ url: /.*domain.*/ });
// Get frame using any other selector
const frameElementHandle = await page.$('.frame-class');
const frame = await frameElementHandle.contentFrame();
// Interact with the frame
await frame.fill('#username-input', 'John');在录制模式下,会自动识别是否是frame内的操作,不好定位frame时,那么可以使用录制模式来找。
具体的相关API和属性可以看这里:https://playwright.dev/docs/api/class-page/
Selector
playwright可以通过 CSS selector, XPath selector, HTML 属性(比如 id, data-test-id)或者是文本内容定位元素。
除了xpath selector外,所有selector默认都是指向shadow DOM,如果要指向常规DOM,可使用*:light。不过通常不需要。
// Using data-test-id= selector engine
await page.click('data-test-id=foo');
// CSS and XPath selector engines are automatically detected
await page.click('div');
await page.click('//html/body/div');
// Find node by text substring
await page.click('text=Hello w');
// Explicit CSS and XPath notation
await page.click('css=div');
await page.click('xpath=//html/body/div');
// Only search light DOM, outside WebComponent shadow DOM:
await page.click('css:light=div');
// Click an element with text 'Sign Up' inside of a #free-month-promo.
await page.click('#free-month-promo >> text=Sign Up');
// Capture textContent of a section that contains an element with text 'Selectors'.
const sectionText = await page.$eval('*css=section >> text=Selectors', e => e.textContent);具体的相关API和属性可以看这里:https://playwright.dev/docs/selectors/
Auto-waiting
playwright在执行操作之前对元素执行一系列可操作性检查,以确保这些行动按预期运行。它会自动等待(auto-wait)所有相关检查通过,然后才执行请求的操作。如果所需的检查未在给定的范围内通过timeout,则操作将失败并显示TimeoutError
如 page.click(selector, kwargs) 和 page.fill(selector, value, kwargs) 这样的操作会执行auto-wait ,等待元素变成可见(visible)和 可操作( actionable)。例如,click将会:
等待selectorx选定元素出现在 DOM 中
待它变得可见(visible):有非空的边界框且没有 visibility:hidden
等待它停止移动:例如,等待 css 过渡(css transition)完成
将元素滚动到视图中
等待它在动作点接收点事件:例如,等待元素不被其他元素遮挡
如果在上述任何检查期间元素被分离,则重试
具体的相关API和属性可以看这里:https://playwright.dev/docs/api/class-page/#page-wait-for-selector
Execution context
API page.evaluate(expression, **kwargs) 可以用来运行web页面中的 JavaScript函数,并将结果返回到plarywright环境中。浏览器的全局变量,如 window 和 document, 可用于 evaluate。
除了操作web页面上已有的界面元素,还可以直接在浏览器上下文中执行自定义脚本,这个就相当于在页面的开发者工具Console中执行脚本。我们通常可利用该功能对网页进行微调操作。
具体的相关API和属性可以看这里:https://playwright.dev/docs/api/class-page/#page-evaluate
学习文档
- https://blog.csdn.net/Code_LT/article/details/120304894 (这是playwright-python的教程
- https://blog.csdn.net/Wfarmer/article/details/111405329 (非常好的实战项目,但也是playwright-python的
- https://jeremyxu2010.github.io/2020/11/web%E6%B5%8F%E8%A7%88%E5%99%A8%E8%87%AA%E5%8A%A8%E5%8C%96%E4%B9%8Bplaywright/ (一篇不错的playwright-node.js教程
- https://playwright.dev/ (最强教程,当之无愧!想要学好,必看此文档
- https://try.playwright.tech/ (在线使用playwright,可以用来新手学习

作者: Marlene