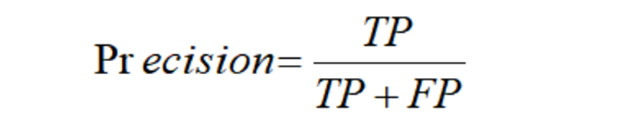
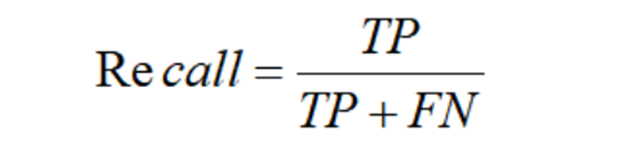
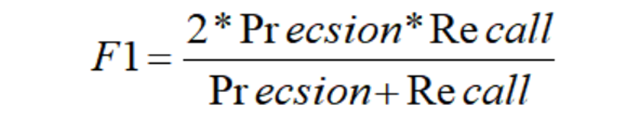

乍一看到某个问题,你会觉得很简单,其实你并没有理解其复杂性。当你把问题搞清楚之后,又会发现真的很复杂,于是你就拿出一套复杂的方案来。实际上,你的工作只做了一半,大多数人也都会到此为止……。但是,真正伟大的人还会继续向前,直至找到问题的关键和深层次原因,然后再拿出一个优雅的、堪称完美的有效方案。—— 乔布斯
新闻人物实体对象和相关事件文本抽取
队伍:数漫蛇山
代码说明
整体代码使用了Paddle、PaddleNLP作为模型处理、训练的框架,所有代码也是在飞浆BML CodeLab 完成运行,非常感谢飞浆对于本队算力一个不可或缺的帮助。
代码结构
数据预处理
这里的数据预处理,主要是处理CLUENER2020的训练数据集和验证数据集。预处理主要是将数据载入DataSet。根据命名实体识别模型的需求,对数据进行BIOS编码,然后转化成索引。然后对数据进行tokenizer和padding操作。
BIOS
BIOS是一种数据标注的方法。在自然语言任务处理中,中文与英文最直观的不同就是中文的词是由一串连续的字组成,词语之间没有像英文那样的天然的空格把词分隔开。因此,大多数中文任务会预先利用工具对中文文本进行分词处理,以词语为单位生成向量表示。NER作为序列标注任务,输出需要确定实体边界和类型。如果预先进行了分词处理,由于分词工具原本就无法保证绝对正确的分词方案,势必会产生错误的分词结果,而这将进一步影响序列标注结果。因此,我们不进行分词,在字层面进行BIOS标注。
标注规则如下:
“B”:(实体开始的token)前缀
“I” :(实体中间的token)前缀
“O”:无特别实体(no special entity)
“S”: 即Single,“S-X”表示该字单独标记为X标签
范例:
{"text": "浙商银行企业信贷部叶老桂博士则从另一个角度对五道门槛进行了解读。叶老桂认为,对目前国内商业银行而言,",
"label": {"name": {"叶老桂": [[9, 11],[32, 34]]}, "company": {"浙商银行": [[0, 3]]}}}
标注后的结果为:
['B-company', 'I-company', 'I-company', 'I-company', 'O', 'O', 'O', 'O', 'O', 'B-name', 'I-name', 'I-name', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'B-name', 'I-name', 'I-name', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O', 'O']
标签索引化
这种直接的标签,计算机代码无法直接使用,需要转化成数字索引,这其实也是一种映射。序列数据的标注采用BIOS的时候,标注的非实体类O不能用0来映射,需要使用非0数字来映射,因为Bert中有个padding需要用到0,不然把padding字符单位和非实体类O字符单位弄混淆了,也会影响最后结果的准确性。标签一共31种。
转化规则如下:
{
"O": 0,
"B-address": 1,
"B-book": 2,
"B-company": 3,
'B-game': 4,
'B-government': 5,
'B-movie': 6,
'B-name': 7,
'B-organization': 8,
'B-position': 9,
'B-scene': 10,
"I-address": 11,
"I-book": 12,
"I-company": 13,
'I-game': 14,
'I-government': 15,
'I-movie': 16,
'I-name': 17,
'I-organization': 18,
'I-position': 19,
'I-scene': 20,
"S-address": 21,
"S-book": 22,
"S-company": 23,
'S-game': 24,
'S-government': 25,
'S-movie': 26,
'S-name': 27,
'S-organization': 28,
'S-position': 29,
'S-scene': 30
}映射后的数据示例:
{'words': ['至',
'大',
'约',
'2',
'0',
'0',
'8',
'年',
'5',
'月',
',',
's',
'a',
'n',
'-',
'h',
'o',
't',
'h',
'k',
'在',
'星',
'展',
'银',
'行',
'的',
'账',
'户',
'内',
'的',
'资',
'金',
'已',
'不',
'足',
'以',
'让',
's',
'a',
'n',
'-',
'h',
'o',
't'],
'labels': [0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
3,
13,
13,
13,
13,
13,
13,
13,
13,
0,
3,
13,
13,
13,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
0,
3,
13,
13,
13,
13,
13,
13]}
Tokenizer
在NLP项目中,我们常常会需要对文本内容进行编码,所以会采tokenizer这个工具,他可以根据词典,把我们输入的文字转化为编码信息,例如我们本文信息是“我爱你”将转化为[2,10,3],其中”我“在字典里对应数字2,”爱“在字典里对应数字10,经过转化之后的文本,就可以作为模型的输入了。
因此我们可以知道如果字典不同,那意味着同一句话编码出来的数字也就是不同的。这里直接使用BertTokenizer。
示例:
tokenizer(text="少轻狂")
{'input_ids': [101, 2208, 6768, 4312, 102], 'token_type_ids': [0, 0, 0, 0, 0]}
如果传入单句话输出的结果是一个字典,其中'input_ids'就是这句话编码后的结果。BERT模型任务中需要在每一句话句首加入[CLS]符号,句尾加[SEP]符号,因此编码会增加2个。
所以为了使得Label标签与input_ids对齐。也要在前面加上一个非实体标签,使两者对齐,在预测结果转成标签时也要跳过第一位数据。
文本数据映射的时候,数据集里含有英文单位,这里要把英文单位用空格隔开,不然BertTokenizer.tokenize(text)不能严格的按照字符来进行映射,这样会影响最后结果的准确性。
Padding
由于每段数据的长度大小不一,会对训练结果产生影响,所以统一padding成相同长度,即在数据后面填充【0】。
由于CLUENER数据集长度均为50,所以将数据统一填充到句子最大长度52(包括[CLS]、[SEP]符号)。如果文本超出最大长度则截断。
最后将数据装入DataLoader,送入模型训练即可。
构建模型
整体模型结构为BERT预训练模型+交叉熵损失函数。
Bert
Bert模型有许多类,这里直接采用bert-wwm-ext-chinese预训练模型。
bert-wwm-ext-chinese是哈工大讯飞联合实验室(HFL)发布在更大规模语料上训练的基于全词Mask的中文预训练模型。该模型在多项基准测试上获得了进一步性能提升。
该预训练模型在CLUENER2020数据集和Thuctc娱乐新闻数据集都取得不错的效果。
由于PaddleNLP对该模型作了比较好的封装,所以代码编写十分简洁明了。
具体结构如下:
BertForTokenClassification(
(bert): BertModel(
(embeddings): BertEmbeddings(
(word_embeddings): Embedding(21128, 768, sparse=False)
(position_embeddings): Embedding(512, 768, sparse=False)
(token_type_embeddings): Embedding(2, 768, sparse=False)
(layer_norm): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(encoder): TransformerEncoder(
(layers): LayerList(
(0): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(1): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(2): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(3): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(4): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(5): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(6): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(7): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(8): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(9): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(10): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
(11): TransformerEncoderLayer(
(self_attn): MultiHeadAttention(
(q_proj): Linear(in_features=768, out_features=768, dtype=float32)
(k_proj): Linear(in_features=768, out_features=768, dtype=float32)
(v_proj): Linear(in_features=768, out_features=768, dtype=float32)
(out_proj): Linear(in_features=768, out_features=768, dtype=float32)
)
(linear1): Linear(in_features=768, out_features=3072, dtype=float32)
(dropout): Dropout(p=0, axis=None, mode=upscale_in_train)
(linear2): Linear(in_features=3072, out_features=768, dtype=float32)
(norm1): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(norm2): LayerNorm(normalized_shape=[768], epsilon=1e-12)
(dropout1): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(dropout2): Dropout(p=0.1, axis=None, mode=upscale_in_train)
)
)
)
(pooler): BertPooler(
(dense): Linear(in_features=768, out_features=768, dtype=float32)
(activation): Tanh()
)
)
(dropout): Dropout(p=0.1, axis=None, mode=upscale_in_train)
(classifier): Linear(in_features=768, out_features=31, dtype=float32)
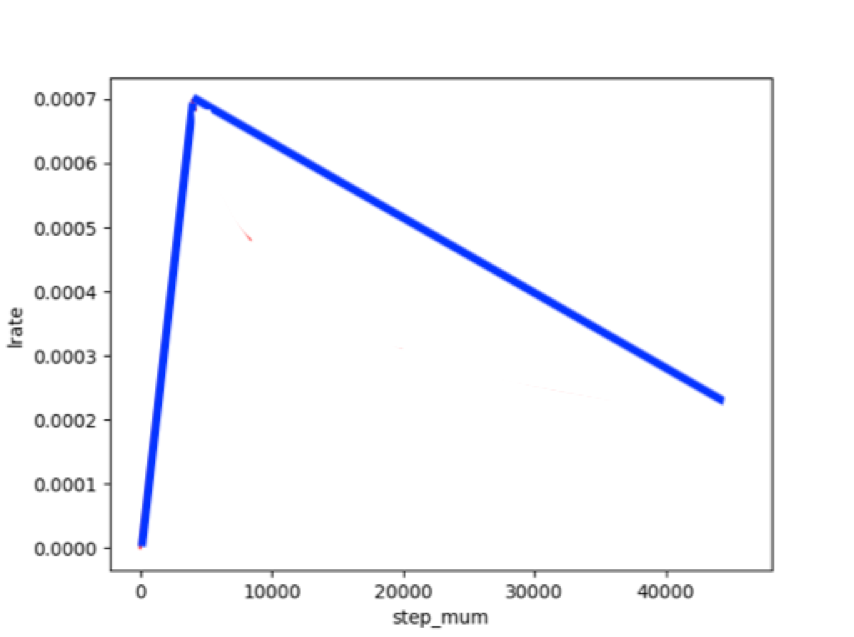
)动态学习率
我们使用cosine schedule with warmup调整学习率。我们将warmup steps设置为总训练轮次的十分之一。因此,学习率会在前十分之一的训练轮次线性递增到设置的学习率数值,在之后下降。
优化器
我们使用AdamW(Adam + weight decay)作为优化器,AdamW是对传统的Adam + L2 regularization的改进。
模型训练
模型训练的过程通常有以下步骤:
从dataloader中取出一个batch data
将batch data喂给model,做前向计算
将前向计算结果传给损失函数,计算loss。将前向计算结果传给评价方法,计算评价指标。
loss反向回传,更新梯度。重复以上步骤。一共10个epoch。
每训练一个epoch时,程序将会评估一次,评估当前模型训练的效果。
每训练一个epoch时,都会将模型参数和tokenizer参数保存一下。
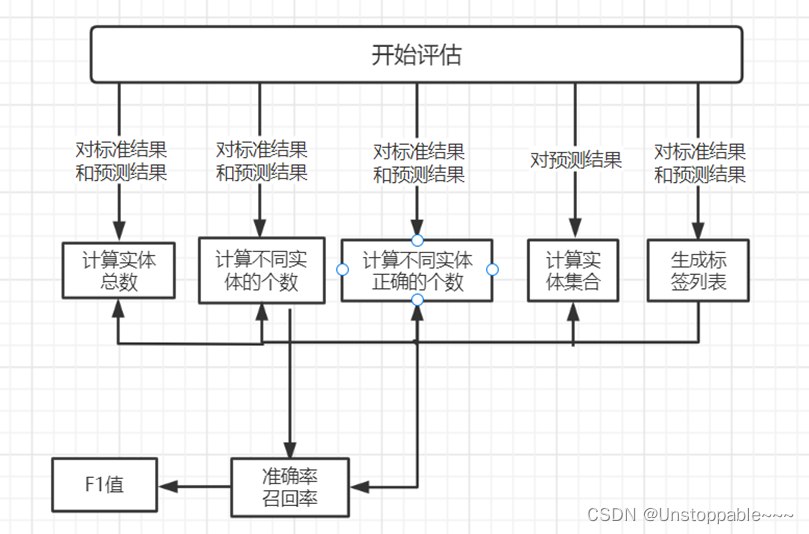
模型评估
主要用于检验模型的状态,收敛情况。在这个过程中使用验证集调整超参数(神经网络的层数和每层神经网络的神经元个数以及正则化的一些参数),这些参数不同选择对模型最终的效果也很重要,我们在开发模型的时候总是需要调节这些超参数,根据几组模型验证集上的表现决定哪组超参数拥有最好的性能。
关于模型好坏的评估只要参考准确率、召回率和F1值。
准确率 = 正确预测的样本数量/预测中所有样本的数量
召回率 = 正确预测的样本数量/标准结果中所有样本的数量
F1值 = 正确率 召回率 2 / (正确率 + 召回率)
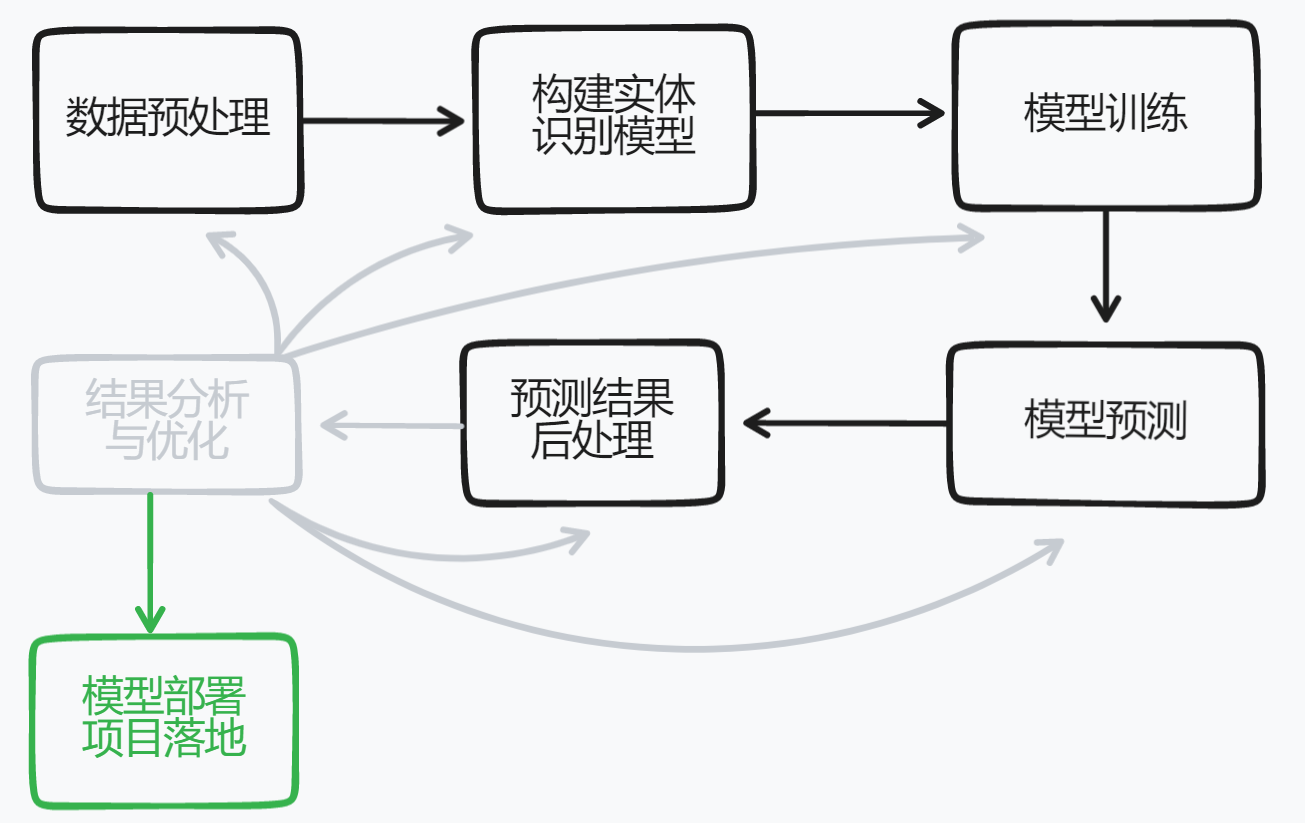
大致流程
模型训练好后F1值最高可达0.87,取得不错的效果,可以基本投入实际应用中去。
模型预测与结果后处理
模型预测主要是对Thuctc娱乐新闻数据集,也就是赛题要求的数据,进行预测。
数据预处理
Thuctc娱乐新闻数据集一共92632篇文章,每篇文章长度不等。数据量较大。由于设备资源有限,无法直接处理,所以对数据集进行分组,总共为31组,前30组每组数据有3000篇文章。
长文本无法直接NER,所以我们对每篇文章采用正则表达式进行分句处理。针对每一句进行命名实体识别。然后再对提取出的实体加以整合。
每句的数据预处理跟测试集和验证集的数据预处理类似,不再重复。
模型预测
本队训练的模型可以识别出人名、地名、电影名等信息,我们只需要人物实体信息的部分。将其提取出来,转成合适格式。
[{'name': '任程伟', 'id': '1099', 'sentences': ['看点1:任程伟突破形象出演居家男']}]别名处理
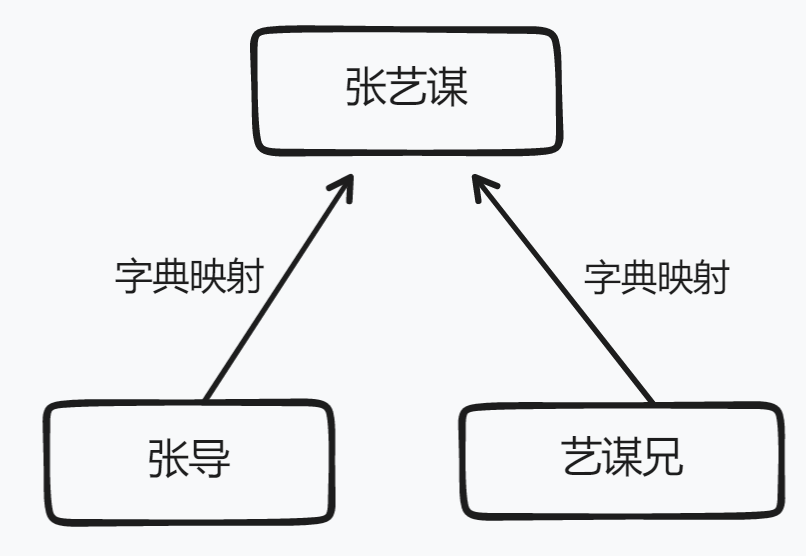
部分文章中,许多实体有别名存在。为了更好的将结果(识别出的实体)加以整合,这里采用字典映射的方式对提取出的实体加以整合,将别名整合至该别名下的实体的数据中。
由于人工建立字典费时费力,所以本队只对部分人物实体建立了别名映射,无法对所有数据中存在别名的实体进行字典映射。
结果
最终通过批量预测,我们一共提取出了532876个实体。
可以看到,人物实体识别的效果可观。
模型部署
我们采用前后端分离的架构,将模型部署到后端,通过前端返回的文本请求处理相应的命名实体识别任务,最终将人物实体数据返回给前端页面展示。
为此,我们特意将其展示在了我们的网站中:http://ner.xyxsw.ltd/
前端
前端主要使用VUE3框架展示页面,高效的MVVM架构和虚拟DOM操作为开发提升了巨大效力,使得我们的模型能够快速展示出来。由于前端页面需要服务器才能渲染服务,无法直接展示,所以相关代码暂不呈放。
后端
后端主要使用基于PYTHON的FASTAPI框架,该框架与法简洁明了,性能非常高,给我们的开发节约了许多时间。由于fastapi需要容器才能启动服务,所以相关代码暂不呈放。
预览
网页可能会根据某些情况有所改动,请以最新版为准。
可以看到,在网页中我们的模型能够有不错的效果,使得模型能够投入实际应用中。
展望
事实上,命名实体识别的应用很广泛,例如在构建知识图谱、搜索等地方能够提供比较好的服务。当然,这只是模型的最初步应用,通过不断深入挖掘,还可以发挥更多的价值。
本队由于时间原因,制作了网页初步展示,事实上,将模型应用在小程序、APP中也是完全没问题。
优化调整与总结
数据预处理
通过我们的实践证明,我们发现,将数据Padding成相同长度,减少不同数据带来的噪声,可以使模型得到更好的效果。
构建模型
我们在选择具体预训练模型的时候,分别测试了ALBERT、MACBERT、BERT-WWM。最终发现BERT-WWM-CHINESE在我们的CLUENER2020数据集中表现最好。
我们尝试了BERT模型外接CRF的结构,理论上通过一层转移矩阵,我们能够更好的提取文本中的信息,使得模型的效果更好。但通过实践发现,这种结构对于直接使用BERT模型,效果微乎其微。于是,我们决定只使用BERT模型。
当然,如果有机会,我们可以尝试一些效果更好的预训练模型和结构,比如说ACL2020的FLAT,基于transformer序列全连接的结构,实现外部词典信息的引入。
模型预测
模型预测不可能完全正确,实际结果也存在部分缺陷和下次。这也是我们日后需要改进的地方,值得我们去进一步优化和反思。
错误1:名字有另外的符号
143318:周慧敏)
167166:(颖颖
190882:“隆裕
163343:张惠妹(
134069:曾恺?
159100:小超人”
错误2:名字缺斤少两
213978:巫启--巫启贤
217073:玛丽亚·--玛丽亚·凯莉
217073:惠特--惠特尼
142241:李嘉--李嘉欣
216291:杰克--杰克逊
216291:迈克--迈克尔
221347:鲍勃·--鲍勃·迪伦
132978:Lol--Loletta
错误3:理解错误
213978:齐贤--“齐贤恋”
156265:赌王(我解释不清楚)
错误4:识别繁体中文出差错
156265:何鸿?--何鸿燊
错误5:原文带特殊符号
198419:杨千?--杨千?、宣萱、黄浩然、邵美琪、薛凯琪、周柏豪等
207281:石?--石?惟妙惟肖的塑造了
总结
最开始我们已经完成了基于pytorch的整体代码,但由于缺失算力,我们不得不借助飞浆AI STUDIO 提供的免费算力。于是,我们将整体代码改成基于Paddle的。
事实上,这是我们队成员第一次接触NLP自然语言处理。这个赛题对我们很有挑战性,也让我们的每位成员提升了许多能力。我们也希望能取得一个不错的成绩。
详细代码

作者: Marlene